|
|

Listen sind natürlich das zentrale Datenelement in AutoLisp,
schliesslich ist der Name Lisp ja ein Akronym für 'List Processing'.
Die Ausstattung an Funktionen zur Listenbearbeitung, die uns
AutoLisp beschert, ist alles andere als üppig, aber völlig
ausreichend.
Listen können aber nicht nur Daten enthalten; auch Funktionen
werden in Lisp als Listen abgelegt - wobei hier allerdings
VisualLisp andere Wege geht als das ursprüngliche AutoLisp.
In VisualLisp haben Funktionen jetzt (wie die 'eingebauten'
Funktionen) einen eigenen Datentyp und können nicht mehr als
Listen verarbeitet werden. Allerdings kann man in VisualLisp
im Bedarfsfall auch Funktionen deklarieren, die als Listen
erhalten bleiben.
Wenn man ernsthafte Anwendungen mit AutoLisp programmieren
möchte, kommt man um ein gewisses Verständnis der speicherinternen
Vorgänge bei der Arbeit mit Listen nicht herum. Jede Liste
hat einen Anfang, der meistens mit einem Symbol verknüpft ist.
Wird das Symbol evaluiert, wird der verknüpfte Speicherzeiger auf
den Listenanfang weiter verfolgt. Die interne Dateneinheit in
Lisp ist immer ein Node, eine Datenstruktur, die
wiederum aus zwei Zeigern besteht: Ein Zeiger zeigt auf die
Daten des Nodes, z.B. eine Zahl oder ein Symbol, der andere
zeigt auf den nächsten Node, den Listennachfolger.
Wenn man beispielsweise mit (nth n datenliste) auf das
n-te Element der Liste datenliste zugreift, passiert
intern im AutoLisp-Interpreter folgendes: Die Evaluation des
Symbols datenliste liefert einen Zeiger auf den Anfang
der Liste. Dieser Anfangs-Node enthält den Zeiger auf das
zweite Listenelement, dieser wiederum den Zeiger auf das dritte
usw. Der Interpreter zählt mit, wie oft von Node zu Node
gesprungen wird. Bei n mal wird der Prozess abgebrochen, jetzt
wird der Datenzeiger des n-ten Listenelementes evaluiert.
Solche Speicherstrukturen nennt man üblicherweise verkettete
Listen, es gibt sie auch in anderen Programmiersprachen.
Dort sind sie allerdings nur im Bedarfsfall vorhanden, die
Regel sind jedoch völlig andere Speicherstrukturen. In Lisp
ist aber vieles auf diese verketteten Nodes aufgebaut! Nicht
nur Listen werden in Nodes abgelegt, sondern auch
dotted pairs und - wie oben erwähnt - auch Funktionen.
Die nachfolgenden Grafiken veranschaulichen die von AutoLisp
verwendeten Speicherstrukturen:
|
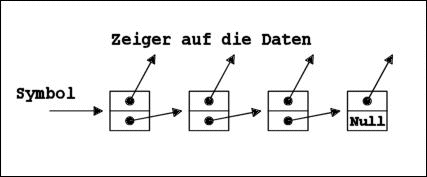
Die Speicherstruktur einer normalen Liste
z.B. (1 2 3 4 5)
|
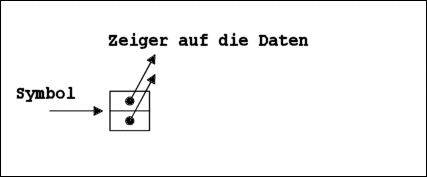
Die Speicherstruktur eines dotted pairs
z.B. (1 . 2)
|
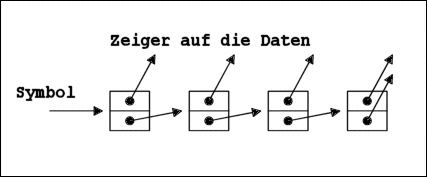
Die Speicherstruktur einer unechten Liste
z.B. (1 2 3 4 . 5)
|
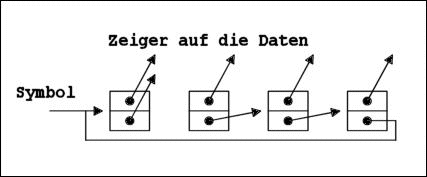
Die Speicherstruktur einer zyklischen Liste
z.B. (1 2 3 4 5 1 2 3 4 5 1 2 ...)
|
Zyklische Listen gibt es übrigens in AutoLisp überhaupt nicht,
es ist unmöglich, sie zu erzeugen. In anderen Lisp-Dialekten
kommen sie aber sehr wohl vor! Unechte Listen lassen sich aber
durchaus erzeugen:
(cons 1(cons 2(cons 3(cons 4 5)))) => (1 2 3 4 . 5)
Wie sieht der Speicher aus, wenn eine Liste Unterlisten enthält?
Die Unterlisten sind selbständige Listen wie andere Listen auch.
Da, wo eine Unterliste in einer Liste enthalten ist, gibt es
einen Node, dessen Datenzeiger auf die Unterliste zeigt. Der
Sachverhalt ist eigentlich ganz einfach, und natürlich wissen wir
auch, dass die Unterliste wieder Unterlisten enthalten kann! Die
nachfolgende Grafik zeigt eine Liste mit einer Unterliste:
|
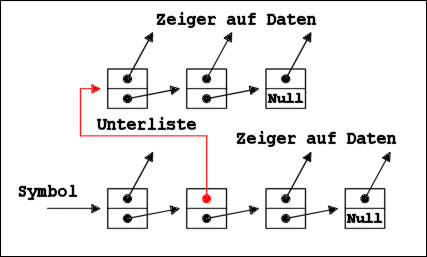
Eine Liste mit einer Unterliste
z.B. (1 2 (4 5 6) 3)
|
|
Die beiden Speicherstellen, die ein Node enthält, haben übrigens
auch Namen: Die Speicherstelle, die die Daten enthält, nennt sich
Address Register, die andere, welche den Zeiger enthält,
heisst Decrement Register. Zum Auslesen des ersteren dient
car (Abk. für Content of Address Register, und
für das andere ist cdr zuständig (Content of Decrement
Register).
In den Grafiken sieht der Speicher ordentlich und aufgeräumt aus,
nachfolgende Listenelemente liegen schön nebeneinander. Das ist
in der Realität aber nicht der Fall! Jeder neu zu erzeugende
Node wird dahin gelegt, wo gerade frei ist. Durch das Freigeben
von Bindungen entstehen Löcher im Speicher, die durch die neuen
Nodes immer wieder aufgefüllt werden. Nach und nach tritt genau
wie bei Festplatten eine gewisse Fragmentierung ein. Dies ist
aber nicht weiter dramatisch: Während bei einer Festplatte durch
zunehmende Fragmentierung die Wege der Leseköpfe immer länger
werden und dadurch der Zugriff ausgebremst wird, spielt das im
Arbeitsspeicher eigentlich keine Rolle.
Nach diesen Erläuterungen wird klar, dass der Interpreter immer
nur auf den Anfang einer Liste zugreifen kann. Von dort aus kann
er sich von Zeiger zu Zeiger durch die Liste hangeln, aber es
gibt keinerlei Möglichkeit, rückwärts zu arbeiten! Die Funktion
(last ...) beispielsweise muss sich (wie alle anderen
Funktionen auch) durch die ganze Liste hindurcharbeiten, um an
das letzte Element zu kommen. Werfen wir noch einen Blick auf
eine weitere Grafik, die verdeutlicht, wie zwei Listen durch
append vereinigt werden:
|
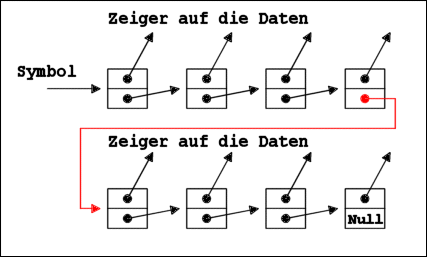
Vereinigung zweier Listen durch (append ...)
z.B. (append '(1 2 3 4 5) '(6 7 8 9 0))
=> (1 2 3 4 5 6 7 8 9 0)
|
Um eine Liste mit append anzufügen, muss also der Interpreter
zunächst einmal die erste Liste bis zum Ende durchlaufen.
Dort wird der bisherige Nullzeiger dann auf den Anfang der zweiten
Liste umgebogen. Die zweite Liste wird nicht mehr durchlaufen.
Die Verhältnisse sind natürlich etwas anders, wenn mehr als zwei
Listen zusammengefügt werden, was mit (append) ja möglich
ist. Die allgemeine Regel lautet daher: Es müssen alle Listen
ausser der letzten durchlaufen werden.
Im Gegensatz dazu ist das Zusammenfügen von Listenelementen
mit (cons ...) nicht so rechenintensiv. Das erste
Argument von cons muss bekanntlich ja ein Atom sein.
Dessen Nullzeiger wird einfach auf das zweite Argument umgebogen,
wenn das zweite Argument eine Liste ist. Es wird also überhaupt
keine Liste durchlaufen, eine einzige Speicheroperation reicht
für ein cons immer aus!
Wenn sukzessive Atome an eine Liste angefügt werden, kann man
es schon als sträflich bezeichnen, wenn dies mit (append ...)
durchgeführt wird. Nehmen wir einmal an, die Liste hat 1000
Elemente, dann sind schon 500500 Zeigeroperationen notwendig,
bis das 1000. Element angefügt ist! Verwenden wir stattdessen
cons, haben wir es mit nur 1000 Zeigeroperationen zu
tun. Da die Liste dann allerdings zum Schluss mit reverse
umgedreht werden muß, kommen noch 1000 Operationen hinzu. Man
kann also abschätzen, dass die cons-Variante etwa
250 mal so schnell sein wird. Wird die Liste noch länger, ändert
sich das Verhältnis natürlich immer weiter zuungunsten von
append!
Wer also auf flotte Programme Wert legt, sollte so etwas:
(while ...
(setq liste (append liste element))
)
schleunigst ersetzen durch das hier (sicherstellen, dass liste
zu Anfang kein Atom ist!):
(while ...
(setq liste (cons element liste))
)
Die 'alte Lispler-Weisheit' dazu lautet: 10 cons und ein reverse
sind besser als ein append.
|
|
|
|